
TCP/IPプロトコルに脆弱性(Ripple20)- 普及ライブラリに問題を発見!どう対処するか
セキュリティ企業JSOFが「Treckが開発したTCP/IPプロトコルのライブラリに、19件の脆弱性が発見された」と発表しました。
JSOF(English)→ https://www.jsof-tech.com/ripple20/
Gigazine(日本語)→ https://gigazine.net/news/20200617-ripple20-vulnerabilities/
既存システムに深刻な脆弱性が!?
Treck…聞き覚えがあったのでJSOFの調査リストを見ると、やはり載っていました。
以前私が担当したある製品では、DigiのNET+OSというOSとTCP/IPプロトコルスタックがバンドルされた、とても便利で有名なプラットフォームを採用しました。
そして、そのTCP/IP部分に使用されていたのがTreckのライブラリでした。
通信部分のデバッグでもしなければ、知らずにいたかもしれませんが、幸か不幸か覚えていました。
その製品はクローズなネットワークでしか使用しないので大丈夫だとは思いますが、やはり不安です。
プロトコルスタックなど、広く利用されて信頼性の高いはずのライブラリにもバグはある
当時の私は脆弱性という目線で見ていなかったのでRipple20の様なものの存在には気づきませんでしたが、バグは見かけました。
メモリなどの資源数がマイナスになってもGetし続けられてしまうというセマフォのバグでした。(詳細は後述します)
イベントフラグなどに置き換えて何とかした記憶があります。
この様に、Ripple20に限らず、既成のライブラリやモジュールにもバグはあるものです。
明確にバグとは言えないが、ちょっと特殊な使い方をするとうまく動かない、ということも良くある話です。
TCP/IP関連で言うと、
「通信の最中に物理的な通信断が発生すると、再接続しても復帰しない」とか
「破損したパケットを受け取るとハングアップする」とか
…結構な悪夢ですね。解決できてよかった。
(これも詳細を後述します。尚、Treckではなく別のメーカのライブラリの話です)
使いまわしたモジュールやライブラリだからこそ、潜んだバグは厄介
極稀にエラーや誤動作、取りこぼしが発生するケース。
これが非常に悩ましいわけです。
そして、これに対してどの様に取り組むか、によってプログラマの隠れた力量が問われます。
- もう発生しないかもしれないし時間もないから無視?
- ライブラリの中を解析してでも、解決する?
- エラー等のトリガを利用してフォローの処理が走るように保険を仕込んでおく?
- 報告だけ挙げて誰かに託す?
- 極稀だし、そんな小さな問題よりも利益に直結する大きな課題に取り組むべき?
どれが正解か?
それは、状況によります。
トラブルに遭遇したとき、チームで状況をシェアし、今取るべき対応を選択する。
そうしなければなりません。
(深夜一人でオフィスに取り残されてる…という状況でもなければ、ですが)
盲目的にならずに、心とスキルを備えておくことが大事
どの手段でも選択できる様、準備をお怠らず、スキルを磨いておくのも重要です。
折々、ハイレベルなコードも読んで向上心を養う、とか。
シンプルな標準ライブラリ(文字列操作関数とか)を見てみるのも良い勉強になります。
新しいOSやプラットフォーム、ライブラリを利用する際、ソースが無いとかブラックボックスになっている部分はありませんか?
ブラックボックスを放置していると、いざという時、手も足も出なくなりますよ?
あなたは、バグの原因がTCP/IPライブラリにあるかも、というシーンに遭遇した時、逃げずに立ち向かえますか?
セマフォ(semaphore)のバグ
限りある資源(メモリ量や処理量)など、最大量が限られる場合に、
無秩序に使ってしまうのではなく、
使用量/返却量を管理するための仕組みがセマフォです。
NET+OSの仕様なのかTreckのライブラリの仕様なのか知りませんが、このセマフォの上限を管理する動作に問題がありました。
資源の上限を10とした場合に、資源が返却される前に11個目の資源を取得しようとした場合、
当然、残り資源は無いとエラーを返すべきですが、どういうわけかOKを返してしまうのです。
確認してみると、資源の残り量がマイナスになっている…ダメでしょ。
資源を管理するのが仕事のはずじゃ…赤字になってもスルーとか。
「なんで?」
この時の「なんで」は
「何でちゃんと動かないのか」ではなく、
「何でこんなバグが放置されてるの!?」という困惑でした。
この時は「送信完了を待つ」という単純な処理にセマフォ(xx_semaphore_get())を使っていただけだったので、
イベントフラグ(xx_event_flags_get())で待つように変更しました。
元のコードを書いた人はセマフォが好きだったんでしょうね。
「送信資源が開くのを待つ」だったらセマフォも悪くないのですが、
「送信完了を待つ」だったらイベントフラグやミューテックスの方が適切です。
TCP/IP関連で遭遇した悪夢
先に少し触れた悪夢、
「通信の最中に物理的な通信断が発生すると、再接続しても復帰しない」
「破損したパケットを受け取るとハングアップする」
これについてお話ししましょう。
現在の筆者はライセンスも許可も持っていないので、メーカ名などは書けませんが、少し対策について触れておきます。
同様なトラブルに遭遇した方の一助になれば幸いです。
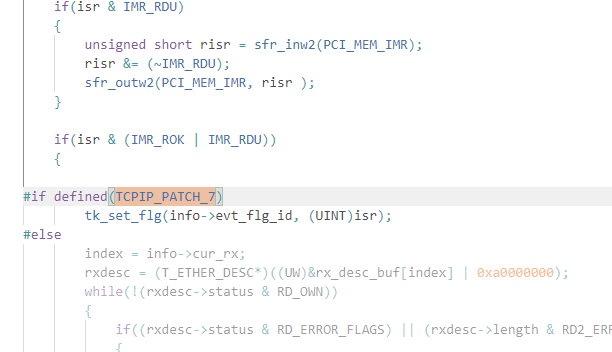
ケース1「通信の最中に物理的な通信断が発生すると、再接続しても復帰しない」
リンクダウンなどの割り込みイベントを、メッセージバッファを使用して上位スタックに通知していた。
しかし、このOS(T-Kernel)では、割込みなどのタスク独立部(タスク内の処理をタスク部、それ以外を全てタスク独立部と呼ぶ)
からタスク部への通信手段(同期手段)として、イベントフラグしかサポートされていない。
その為、タイミングによってはメッセージバッファによる通知が失敗に終わるなどの問題が生じる。
そこで、割込み処理からタスク部までは、イベントフラグで通知し、
そのフラグを受け取ったタスク部から上位スタックへ
メッセージバッファで詳細情報を送る、という形に修正した。
仕様の異なる別のOSから移植した際に漏れていたのだと思われます。
OSの仕様とプロトコルスタックの仕様の齟齬によるものだったので
(それを吸収するのが本来のラップの役割だが)
原因に辿り着くまでが大変でした。
しかし、この対策により(ケーブル接続トラブルなどの物理的な通信断以外にも)、
想定外の(PCIなど電気的な)通信トラブルまで一緒に改善されたので爽快でした。
ケース2「破損したパケットを受け取るとハングアップする」
RealtekのEthernetチップに対応するためにラップした物でしたが、破損エラーに対するフラグが漏れていた様子です。
RCRレジスタのAERビットがOFFだったのでONに修正し、改善されました。
結果だけ書くとあっさりしたものですが、答えに辿り着くのがまた大変でした。
上位アプリからプロトコルスタック、ドライバに至るまで、ほとんどのソースや仕様をひっくり返して調べ、
挙句の果てにEthernetチップのハードウェア仕様書を読み解く羽目になり…
そもそも、「破損したパケットを受け取る」という発生条件は後から分かった話であり、
最初は「何だかシステムをまともに使い始めるとダウンする。何が起こってるのかさっぱりわからない」というところからのスタートでした。
いや、ほぼほぼ終盤までその状態でほとんどカンで探り当てた感じ。
我ながら良く見つけたもんだと思います。
しかし、こういったケースもそれほど珍しくないのですよね…
やれやれ。
ではみなさん、また。がんばっていきましょー!